
Matéria original do Extreme Tech
Traduzida por Marcus Sarmanho Hermes Marques
Editor chefe PC Facts
Depois de explicado tudo que envolve os Assynchronous Shaders, você já poderá entender porque as AMD GCN arrebentaram no Ashes of Singularity
Asynchronous Shaders são algumas coisas que deveriam ter chegado há muito tempo porque tudo que temos feito é jogar mais energia ao problema do que utilizar essa energia de maneira mais eficiente.
A AMD vem trabalhando junto à Microsoft no DirectX 12 e futuramente poderemos ver quão bem suas placas irão suportar alguns recursos desta API. Um exemplo é os até agora chamados "Asynchronous Shaders," que são uma maneira diferente de manipular as tarefas em comparação às placas antigas que se mostra potencialmente mais eficiente.

Em DirectX 11, há duas maneiras principais para gerenciar as tarefas sincronizadamente: gráficos multi threaded e gráficos multi threaded com preempção e priorização, cada uma com suas vantagens e desvantagens.
Antes de continuar, devemos esclarecer alguns termos. Os Shaders das GPUs fazem os desenhos da imagem, calculam a física dos jogos, pós processamento dentre outras coisas e os fazem ao serem demandados com várias tarefas. Estas tarefas são entregues através da transmissão de comandos, que é a linha de comando principal que os Shaders precisam executar. A transmissão de comando é gerada juntando queues individuais de comando que consistem em múltiplas tarefas e espaços de quebra.
Esses espaços vazios no queue existem porque as tarefas em queue único não são geradas uma após a outra em gráficos multi threaded; tarefas em único queue são as vezes geradas somente depois de todas as tarefas em outro que é serem geradas. Por conta desses espaços vazios, um queue simples não pode usar os Shaders em seu potencial máximo.
De maneira geral, há três queues de comando: o gráfico, computacional e o de cópia.

A maneira mais simples de descrever como gráficos multi threaded síncronos funcionam é dizendo que os queues de comando são fundidos variando a geração entre um e o outro em intervalos de tempo - um queue vai para a transmissão de comando principal primeiro, para então o próximo seguí-lo e por aí vai. Entretanto, os espaços mencionados acima permanecem na linha de transmissão principal, ou seja, a GPU nunca vai estar a 100% de sua carga real. E mais: se uma tarefa urgente aparecer, deve se juntar a linha de comando e esperar que o resto dos comandos terminem para ser executada. Outra maneira de pensar nisso é comparando a múltiplas fontes em um semáforo se espremendo em uma única faixa.

Isso nos leva ao nascimento da preempção e priorização, que funcionam da mesma maneira que os gráficos multi Threaded síncronos, mudando apenas o fato de que tarefas urgentes são priorizadas. Mais especificamente, quer dizer que a linha de comando principal pode ser pausada para dar passagem para as tarefas urgentes, sendo estas executadas com a menor latência possível. A pegadinha, entretanto, é que todas as outras tarefas tem de ser paralisadas, o que pode levar a problemas de performance por troca de overhead. Acrescente-se que o problema com os espaços vazios permanece, logo ainda há espaço para melhorias. Você poderia pensar na questão do semáforo acima da mesma forma só que com uma passagem para ambulâncias.
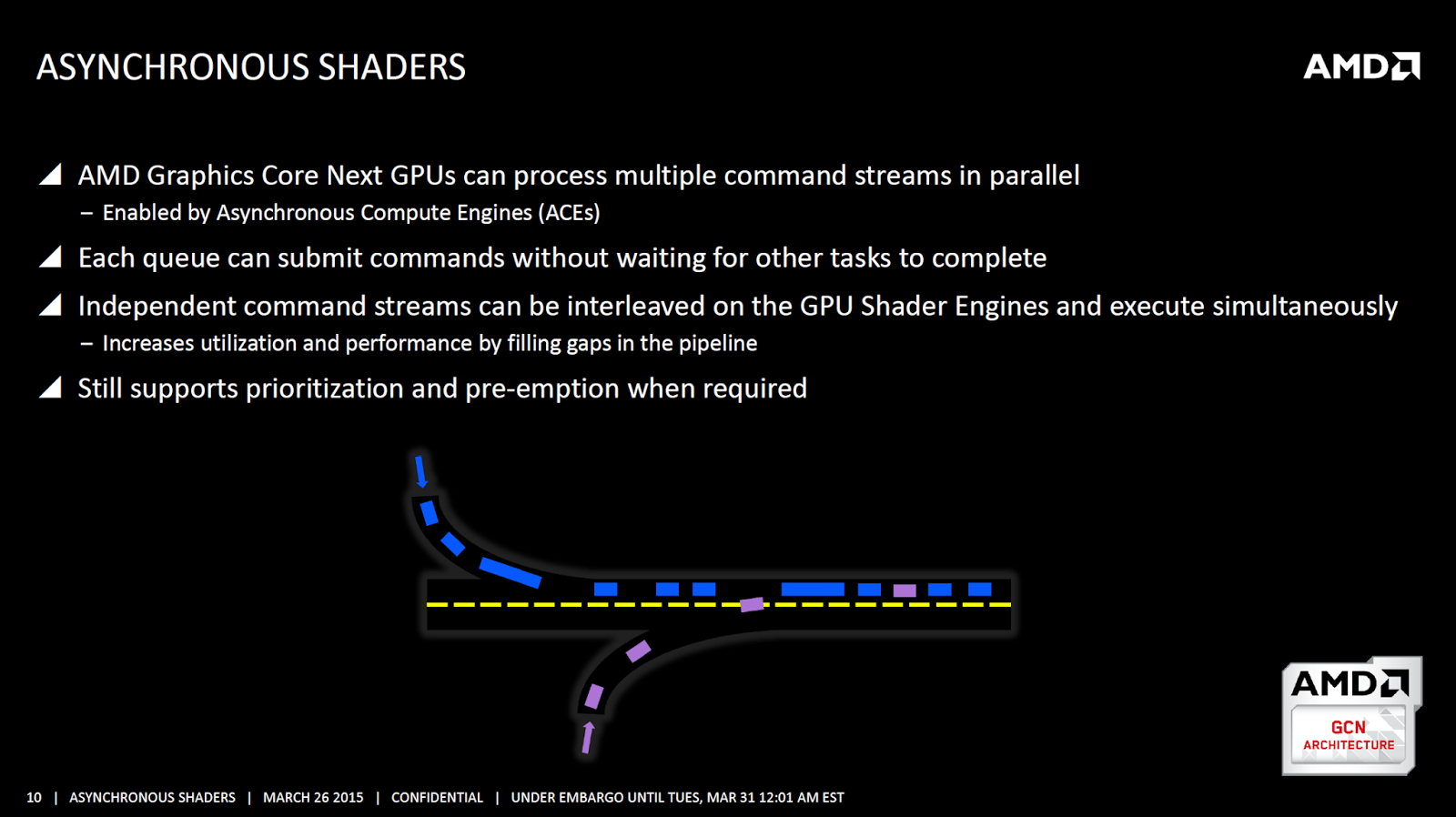
Em DirectX 12, entretanto, um novo método de junção das tarefas chamado de Asynchronous Shaders está disponível, que é basicamente gráficos multi threaded assíncronos com preempção e priorização. O que ocorre aqui é que as ACEs (Asynchronous Compute Engines) nas GPUs AMD baseadas em GCN vão entrelaçar as tarefas, preenchendo os espaços vazios na linha de comando com outras tarefas. Não precisa explicar muito para entender que isso nos leva a um ganho de performance.
Nas GPUs AMD com GCN, cada ACE pode controlar até seis queues e cada ACE pode endereçar sua própria parcela de shaders. As placas mais básicas tem apenas 2 ACEs, enquanto as mais elaboradas tem oito.

Para trazer números a mesa, AMD rodou o demo da SDK do Liquid VR, que rodou a 245fps com Assynchronous Shaders e pós processamento desligados. Com pós processamento ligado, caiu para 158. Ligando depois o assynchronous shaders saltou para 230 FPS, quase a performance original. Claro, isso é o cenário mais perfeito possível, mas isso pode significar que você pegou efeitos de pós processamento quase que de graça...
De todo modo, a grande razão pela qual os Assynchronous Shaders são interessantes é o claro aumento de performance. Eles não serão apenas capazes de garantir que todos os espaços vazios na linha de comando serão preenchidos para melhorar a performance, mas também, a forma como as ACEs vão poder preencher e trabalhar com as tarefas irá reduzir o timing e a latência. Basicamente, o aumento do paralelismo e a nova headroom garantirão que mais frames cheguem às telas ainda mais rápido, o que pode ser especialmente interessante para propósitos como os do VR.
Com o VR demandando resoluções mais altas do que as que víamos antes como uma experiência confortável e exigindo também maior framerate pra reduzir as dores de cabeça, minimizar náuseas e aumentar a imersão, chegamos a um ponto em que precisamos de mais poder de GPU do que nunca antes visto. Neste momento, trazer GPUs mais potentes, simplesmente não funciona mais; as GPUs precisam se tornar mais poderosas sim, mas elas também precisam ser mais eficientes.
É tudo trabalho da AMD? Provavelmente não, mas a companhia está trabalhando ao lado da Microsoft para garantir o melhor suporte possível. Durante o briefing, o orador mencionou que não tinha informações sobre o suporte de seu competidor, mas sabemos que a NVIDIA é sempre "cof cof" sobre produtos não anunciados. Adendo aqui: o Assynchronous Shaders não é um recurso novo apenas para o DirectX 12; será parte da nova API Vulkan bem como da Liquid VR e já é citaste no Mantle.